

Qwen AI is Alibaba Cloud’s family of large language models, originally launched as Tongyi Qianwen in April 2023 and now one of the most downloaded open-weight AI ecosystems on the planet. Built and maintained by Alibaba’s Qwen Team, the series spans everything from a 0.6 billion parameter edge model you can run on a laptop to a 480 billion parameter coding behemoth designed for enterprise agentic pipelines.
The key differentiator that sets Alibaba Qwen apart from OpenAI, Anthropic, and Google is this: the core models are open-source under an Apache 2.0 license, meaning you can download, fine-tune, and self-host them without paying anyone a cent. I spent time testing Qwen AI across the Qwen Chat consumer interface, the API, and the coding-specialized Qwen Coder models, covering writing tasks, long-document analysis, multilingual work, and code generation. Here’s what I actually found.
What Is Qwen AI? The Model Family Explained
Qwen is not a single model. It’s an entire lineup, and understanding how it’s structured is the difference between picking the right tool and wasting two hours running the wrong one.
At the core, you have the general-purpose text models: Qwen3 dense variants ranging from 0.6B to 32B parameters, and MoE (Mixture-of-Experts) variants at 30B-A3B and 235B-A22B. The MoE architecture is worth understanding.
Instead of activating all parameters for every query, these models activate only a fraction of their total weights per task. The 235B-A22B flagship, for instance, activates just 22 billion of its 235 billion parameters per forward pass. That’s why it can run at competitive speeds and costs compared to much smaller dense models.
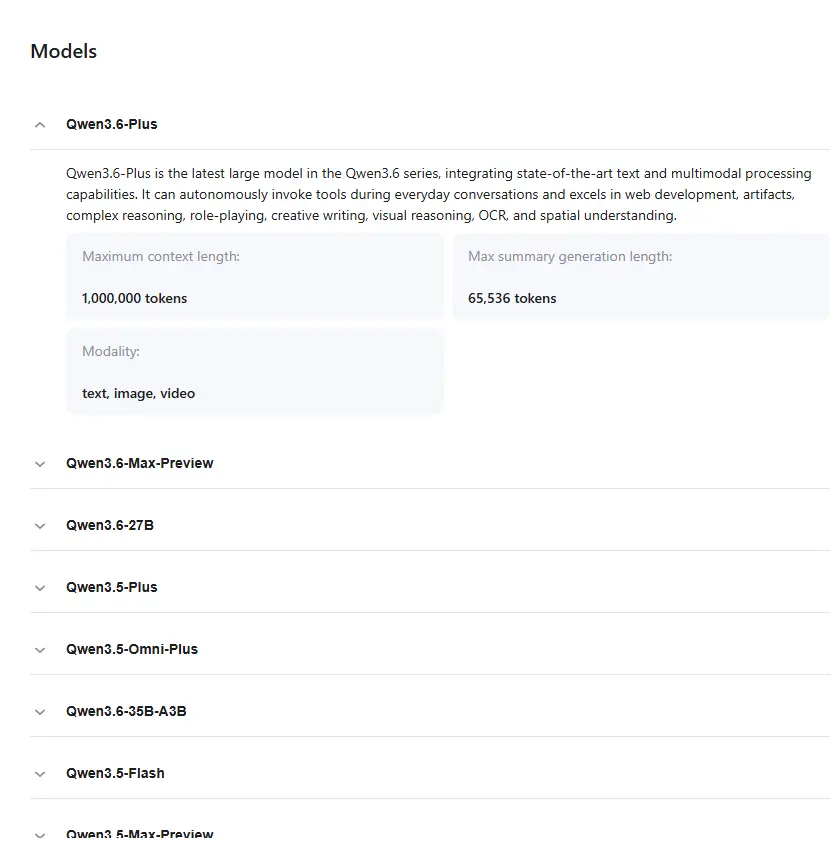
Beyond the base text models, the family branches into specialists:
- Qwen3-Coder: fine-tuned for software development, agentic coding, and long-context code understanding. The flagship variant hits 480B-A35B parameters.
- Qwen3-Omni / Qwen3.5-Omni: a native multimodal model handling text, image, audio, and video simultaneously. More on this below.
- Qwen-VL: vision-language models for image understanding and analysis.
- Qwen-Audio: specialized for transcription, sentiment detection from tone, and audio reasoning tasks.
One feature that genuinely stands out is the hybrid thinking mode introduced with Qwen3. You can switch between a deliberate “thinking” mode (which reasons step-by-step before answering, burning more tokens but improving accuracy on hard problems) and a “non-thinking” mode for fast, low-cost responses. In practice, this means you’re not forced to choose between a cheap-but-shallow model and an expensive reasoning model. The same model adapts. That’s a meaningful UX improvement over having to juggle separate model endpoints, and it’s something neither GPT nor Claude currently offers in quite the same way.
As of mid-2026, the Qwen model family supports 119 languages and dialects. The flagship open models carry context windows of 128K tokens natively (extendable to 131K via YaRN), while proprietary API tiers push to 1 million tokens. For reference, 128K tokens handles roughly 96,000 words, about the length of a full novel.
Qwen Chat: The Consumer Interface
Qwen Chat (accessible at chat.qwen.ai and qwen.ai) is Alibaba’s answer to ChatGPT and Claude.ai. What it’s officially called internally is Qwen Studio, a unified platform giving both everyday users and developers access to the full model lineup in one interface.
The feature set is broader than most people expect. Through the browser interface, you get:
- A standard chatbot powered by your choice of Qwen model
- Image and video understanding (upload a screenshot, a chart, a short clip)
- Image generation and editing
- Document processing (PDF, DOCX uploads for Q&A or summarization)
- Web search integration
- Voice and video chat
- Artifacts: structured outputs like code blocks, tables, or formatted documents rendered in a side panel
The free tier is genuinely useful. Alibaba provides 1 million free tokens per model, valid for 180 days after activation. That’s enough to run hundreds of full conversations, test the model seriously across task types, and form a real opinion before committing to anything paid.
The interface itself is clean and functional. It doesn’t have the polish of Claude.ai, with no memory management, no project organization, and no persistent context across sessions in the way Claude’s Projects feature works. The model selector is prominent, which is useful when you know what you’re doing, but the sheer number of model options (Qwen3-235B, Qwen3-30B, Qwen-Max, Qwen-Plus, Qwen-Turbo, and more) will genuinely confuse first-time users who just want a capable AI assistant without reading a spec sheet.
Compared to ChatGPT, Qwen Chat has better out-of-the-box multilingual support and a more generous free tier. Compared to Claude.ai, it lacks the writing quality polish and the more intuitive conversation management. For developers who want to test models before building on the API, it’s a solid sandbox. As a daily-driver consumer tool for non-technical users, it’s a step behind the Western alternatives.
Qwen Coder: How Good Is It Really?
This is where the Qwen Coder conversation gets most interesting, and where the gap between benchmark claims and real-world use matters most.
The headline number: Qwen3-Coder achieves 69.6% on SWE-Bench Verified. SWE-Bench tests models against actual GitHub issues pulled from real open-source projects. The model receives a bug report and a codebase, and has to implement a fix that passes the existing test suite. At 69.6%, Qwen3-Coder places among the top coding models globally, a legitimately impressive result (this matched findings from independent benchmark analysts, including the preprints.org comparative study from August 2025).
On the mathematical reasoning side, Qwen3 models score 81.5 on AIME 2025, which is relevant to code because algorithm design and complex logic problems map closely to competition math reasoning.
Where things get more complicated is the greenfield vs. debugging split.
When I tested Qwen3-Coder on writing new Python functions from scratch, with clean specifications and clear inputs and outputs, it performed well. Fast, structured, readable code with appropriate comments.
On standard medium-difficulty tasks, independent evaluations (16x Eval’s August 2025 coding benchmark) confirm it matches premium proprietary models.
But ask it to debug existing code, trace through a complex refactor, or handle an edge-case language feature, and performance drops noticeably. The 16x Eval TypeScript narrowing task is a concrete example: on an uncommon type narrowing challenge, Qwen3-Coder scored 1/10, the same as Kimi K2 and DeepSeek V3 (New).
Claude Sonnet 4 scored 8/10 on the same task. Multiple Reddit threads and the eesel AI review echo this: Qwen builds new things well but can struggle when asked to fix the old thing you already have (consistent with what multiple users and independent reviewers reported across forums and blog posts).
The other honest observation from agentic coding comparisons: Qwen 3.6 Plus, the proprietary mid-tier model, is competitive with Claude Sonnet for multi-step automated workflows, but falls behind GPT-4.1 and Claude 4 models when tasks require nuanced reasoning about complex system interactions. It’s a capable second-tier agentic coder, not yet the default choice for the most demanding production pipelines.
One genuinely impressive spec: the Qwen3-Coder 480B-A35B flagship supports a 1 million token context window. That’s the ability to ingest an entire large codebase in a single pass, something most competitors cap well below.
Performance Across Tasks: What It Actually Does Well (and Doesn’t)
Math and Reasoning
Qwen3’s AIME 2025 scores and its performance on reasoning benchmarks are legitimate strengths. The hybrid thinking mode helps significantly here: switching to thinking mode for a multi-step probability or calculus problem produces noticeably more reliable step-by-step solutions than non-thinking mode. This is a real advantage for developers working on algorithm-heavy projects or data analysis pipelines. For mathematical reasoning specifically, independent benchmark summaries from summer 2025 placed Qwen3-32B at 11th globally, just above Claude 3.7 Sonnet Thinking on the same leaderboard.
Writing and Content Generation
Serviceable, not exceptional. Qwen AI produces content writing that doesn’t immediately read as AI-generated. Tone is natural, structure is logical. For blog posts, summarization, and straightforward professional writing, it gets the job done. Where it falls behind Claude in particular is nuanced instruction-following: ask it to write in a very specific editorial voice with precise stylistic constraints, and it tends to drift. It handles the task but loses the texture.
Multilingual Work
This is a genuine, clear-cut strength. Qwen’s 119-language support isn’t just marketing. The models were trained on large non-English corpora, and performance on Asian languages (Chinese, Japanese, Korean) is noticeably stronger than most Western-developed alternatives. For teams building multilingual applications or working across language markets, this is a real differentiator.
General Factual Recall: A Documented Problem
Here’s something that gets underreported in the benchmark coverage: Qwen3 hallucinates more on broad popular knowledge queries than Qwen2 did. This is not a minor caveat. It’s a documented regression raised in active discussions on the Qwen3-235B HuggingFace model page. One community contributor tested it against a straightforward question about the cast of a popular Canadian TV show: Qwen2-72B answered correctly; Qwen3, despite being far larger, produced a hallucination-filled response. The same pattern shows up on SimpleQA benchmarks, where Qwen3’s scores are notably weak. The apparent cause, discussed in that thread: overtraining on coding and math tasks appears to have displaced some of the model’s general world knowledge. It’s a real tradeoff, not a theoretical one, and it matters if your use case goes beyond code and numbers.
Qwen Omni: The Multimodal Play
Released March 30, 2026, Qwen3.5-Omni is Alibaba’s attempt to build a single model that genuinely handles text, image, audio, and video, not by stitching separate encoders together, but through a unified native architecture.
The technical design centers on a Thinker-Talker framework. The Thinker processes all incoming inputs: text, images via a vision encoder, and audio via a native Audio Transformer (AuT) trained on over 100 million hours of audio-visual data. The Talker generates real-time speech output. It’s not a bolt-on voice wrapper; it’s architecturally integrated.
The practical specs are substantial: 256K token context, which translates to over 10 hours of audio or around 400 seconds of 720p video at 1 FPS. Speech recognition across 113 languages, speech generation in 36. The model ships in three variants (Plus, Flash, and Light) covering different speed and cost tradeoffs.
Alibaba’s own benchmark claims are strong: Qwen3.5-Omni-Plus achieves state-of-the-art results across 215 audio and audio-visual understanding subtasks, reportedly surpassing Gemini 3.1 Pro in key audio tasks. I want to be transparent here: these are Alibaba’s reported numbers from their technical report, and independent third-party replication at this scale is still catching up. What multiple external reviewers have confirmed is that audio understanding, specifically recognition, translation, and dialogue tasks, is a genuine competitive strength against Gemini’s multimodal offering.
One feature worth highlighting is Audio-Visual Vibe Coding. You can record your screen, narrate what you want built, and hand the full video to Qwen3.5-Omni, which watches, listens, and generates code based on the combined visual and audio input. It’s an early-stage capability, but it’s the most literal interpretation of “show, don’t tell” development I’ve tested.
No comparable open-weight model from DeepSeek, Mistral, or Meta’s Llama family has anything in the same category right now. In the omnimodal space, Qwen AI is genuinely ahead among open-source options.
Alibaba Qwen AI Pricing: API, Free Tier, and Where It Gets Complicated
The free tier is the easiest part: Qwen Chat gives you 1 million free tokens per model at registration, valid 180 days. For casual testing and personal use, most people won’t exhaust this.
API pricing (as of 2025, via Alibaba Cloud DashScope) is structured as follows:
| Model | Input (per 1M tokens) | Output (per 1M tokens) |
|---|---|---|
| Qwen-Turbo | $0.05 | $0.20 |
| Qwen-Plus | $0.40 | $1.20 |
| Qwen3-30B | $0.20 | $0.80 |
| Qwen3-235B (flagship) | $0.70 | $2.80 |
These are competitive numbers. Qwen-Turbo at $0.05 per million input tokens undercuts most alternatives at similar quality. Third-party providers like DeepInfra and OpenRouter often go lower still: DeepInfra’s rates for Qwen models run 50-80% cheaper than major cloud platforms, making them the cost-conscious developer’s first stop.
Where it gets genuinely confusing: Alibaba’s official pricing page has reportedly returned “Not Found” errors, making it difficult to find authoritative current numbers without digging through DashScope documentation directly. Pricing also tiers based on prompt length, with queries over 200K tokens triggering different rates. And “thinking mode” costs more than non-thinking mode on the same model.
The practical gotcha for developers building conversational applications: because AI models have no persistent memory, every message turn requires re-sending the full conversation history. In a long support chat thread, your input token bill compounds fast. It’s an issue with every LLM API, but worth factoring into Qwen AI cost projections specifically given that some models have lengthy thinking traces that add to output token counts.
Setting Up Qwen AI: Self-Hosting vs. Qwen Chat vs. API
This is the flexibility that genuinely separates Qwen AI from most competitors, and it’s worth walking through practically.
Option 1: Qwen Chat (qwen.ai) Zero setup. Sign up, pick a model, start chatting. Best for individual users, rapid experimentation, and non-technical teams. The limitation is that your data runs through Alibaba’s infrastructure (see the section below on data privacy).
Option 2: Alibaba Cloud API (DashScope) Standard API integration with an OpenAI-compatible endpoint structure, which means you can swap it into existing LLM pipelines without rewriting your SDK calls. Best for product teams building applications and developers who want managed hosting without the overhead of running GPUs. The limitation is that it’s still subject to Alibaba’s data handling practices.
Option 3: Self-Hosting (Ollama, vLLM, HuggingFace Transformers) Because the model weights are open under Apache 2.0, you can download and run Qwen AI locally or on your own servers. The community has built solid tooling around this: Ollama handles single-user local deployment in minutes; vLLM handles high-throughput production inference with PagedAttention for multi-user scenarios. For a quick self-hosted setup, Railway’s Qwen3 template deploys Ollama plus OpenWebUI with pre-configured networking in about two minutes. Best for enterprises with strict data residency requirements, developers who need full control over the model, and teams running air-gapped environments. The limitation is hardware: meaningful Qwen3 models start requiring serious VRAM, and running Qwen3-32B comfortably means A100-class or equivalent GPUs.
The Apache 2.0 license is the key detail here: it permits unrestricted commercial use and fine-tuning. You are not locked into a single vendor’s pricing or terms, which is a structural advantage no proprietary model can match.
Qwen AI Alibaba vs. DeepSeek: Which Chinese Open-Source Model Should You Use?
This is the comparison that comes up constantly in developer communities, so it deserves a direct answer rather than a hedge.
Both Qwen and DeepSeek are Chinese-developed open-weight models with Apache 2.0 licensing. Both are dramatically cheaper than GPT-4o or Claude for API usage. The choice comes down to use case.
For coding tasks: Qwen3-Coder is the stronger choice for agentic workflows and long-context code understanding, especially with its 1M token context window. DeepSeek R1 remains competitive on raw code generation and offers a better cost-to-performance ratio for self-hosted deployments per the August 2025 preprints.org comparison, running at notably lower power consumption per token than Qwen3-Coder on equivalent hardware.
For general reasoning: Qwen3-235B-A22B (Thinking) outperforms DeepSeek-R1 on 17 of 23 benchmark tasks per the Qwen3 technical report, particularly on mathematics and agent tasks. This gap has widened since DeepSeek-R1-0528 was released as only an incremental improvement; independent community benchmarks place it below Qwen3-32B on agentic scoring.
For censorship sensitivity: Both models apply Chinese government-mandated filters on politically sensitive topics including Tiananmen Square, Taiwan, and Xinjiang. One independent analysis of 72B-class versions found that outside of explicitly triggered “party line” responses, meaningful bias in general queries was hard to detect. But for applications where users might navigate politically adjacent topics at all, this is a documented constraint of both models, not a solvable one.
Bottom line: Qwen AI Alibaba wins on multimodal (Omni), multilingual breadth, and agentic coding context length. DeepSeek wins on raw inference cost efficiency for self-hosted setups. Both beat proprietary models on price-per-token for comparable performance tiers.
Two Real Limitations You Should Know Before Committing
Limitation 1: General Knowledge Hallucinations Are Getting Worse, Not Better
This one surprised me, and it’s buried under all the benchmark enthusiasm.
Qwen3 hallucinates more frequently on broad factual queries than its predecessor Qwen2 did. This isn’t speculation. It’s directly documented in the Qwen3-235B HuggingFace community discussion thread, where multiple developers reproduced the regression with concrete examples. One posted a straightforward question about a well-known TV show cast: Qwen2-72B answered accurately; Qwen3, despite being significantly larger and more capable on coding benchmarks, hallucinated the cast entirely. SimpleQA scores, which test factual accuracy on real-world knowledge questions, are notably low across the Qwen3 family.
The apparent mechanism: aggressive optimization for coding and math performance appears to have displaced some of the model’s general world knowledge. The tradeoff is real and currently unresolved. For any application where factual accuracy on open-domain questions matters, including customer support, journalism tools, and research assistants, this is not a minor footnote. It’s a reason to either pair Qwen with retrieval-augmented generation (RAG) or reconsider whether it’s the right model for the job.
Limitation 2: Your Data Lives on Chinese Infrastructure, and That’s a Real Business Risk
Using Qwen Chat or the DashScope API means your prompts are processed on Alibaba Cloud infrastructure, which operates under China’s Cybersecurity Law, Data Security Law, and Personal Information Protection Law (PIPL). Under these laws, Alibaba can be compelled to provide data to Chinese authorities, even data stored on Singapore-based nodes.
The March 2025 Terms of Service explicitly authorize Alibaba to use the “non-personal” portions of user prompts for model training. In practice, personal and non-personal data intermingle in most prompts, so the realistic assumption is that anything you type may help train the next Qwen version. There is no fixed deletion window in the privacy policy, unlike OpenAI’s 30-day API rule, and Alibaba does not currently have an EU GDPR representative, making enforcement of European data rights practically uncertain (documented by The Firewall cybersecurity blog and independent privacy analysts, March 2025).
This isn’t a hypothetical concern dressed up as a warning. It’s a documented structural issue that has led multiple organizations to restrict Qwen usage on internal or sensitive workloads. The answer for teams with genuine data residency requirements is self-hosting the open-source weights, which is entirely possible with Apache 2.0, but that option requires hardware and engineering investment. The convenience of the managed API comes with this tradeoff attached.
Who Should Use Qwen AI and Who Shouldn’t
Use Qwen if:
- You’re building multilingual applications and need native, well-trained support across 100+ languages. Qwen genuinely outperforms most alternatives here.
- You want open-source flexibility: the ability to self-host, fine-tune, and deploy commercially without licensing restrictions.
- You’re a developer evaluating cost-efficient API alternatives to GPT-4o or Claude for code generation and agentic workflows.
- Your team needs a 1M-token context window for large codebase ingestion and Qwen3-Coder fits the pipeline.
- You’re interested in multimodal capabilities, particularly voice-plus-vision, without paying Gemini or GPT rates.
Reconsider Qwen if:
- Your use case requires consistent factual accuracy on open-domain knowledge questions. The Qwen3 regression here is real and not yet fixed.
- You’re in a regulated industry (healthcare, legal, financial services) with data residency requirements that preclude Chinese cloud infrastructure, and self-hosting isn’t feasible for your team.
- You’re a non-technical user looking for a polished, low-friction daily AI assistant. Qwen Chat works but doesn’t match the UX quality of ChatGPT or Claude.ai.
- Your workflows require debugging and refactoring of existing complex codebases rather than greenfield code generation.
The Bottom Line on Alibaba Qwen
Qwen AI is the most serious open-source AI ecosystem available right now, and it’s not particularly close. The download numbers, approaching 1 billion model pulls by early 2026 and accounting for over 50% of all open-source model downloads globally per Alibaba’s figures, reflect genuine developer adoption, not just hype. The Apache 2.0 license, the model range from 0.6B to 480B parameters, the hybrid thinking mode, and the 1M-token context on Qwen3-Coder are all legitimately differentiated.
But “best open-source option” is not the same as “best option.” For greenfield coding and multilingual applications, Qwen earns serious consideration against any model, proprietary or otherwise. For factual accuracy tasks, for sensitive enterprise data, and for users who need a polished consumer experience, it has real and documented gaps.
The most honest recommendation: if you’re a developer or technical team, run the Qwen Chat free tier on your actual use cases for a week. The 1M free tokens are enough to form a real opinion. Self-host if data privacy is a hard requirement. Use the API if you’re building on top of it. But go in knowing that the hallucination regression in Qwen3 is real, that the data jurisdiction question has no convenient answer, and that on the hardest coding edge cases, Claude Sonnet 4 still has an edge.
Qwen is not a compromise. It’s a legitimate choice with legitimate caveats.
Similar AI Tools

Poe AI: The All-in-One AI Toolkit That Puts Every Major Model in One Place

Grok AI – Artificial Intelligence Tool

DeepSeek Ai The Free AI That Actually Competes With GPT-5
