

Kimi Code Review 2026 Is K2.7 the Best Open-Source Coding Agent for the Price?
Moonshot AI’s Kimi Code has built a reputation in developer circles as the cost-efficient alternative to frontier closed models. The release of Kimi K2.7 Code on June 12, 2026 sharpens that pitch considerably this is a focused coding upgrade that cuts reasoning token usage by 30% while posting double-digit gains on Moonshot’s internal benchmarks. The question worth answering before committing to a subscription or a large-scale API deployment is whether those numbers hold up against independent scrutiny, and whether the cost advantage justifies the trade-offs that real users have documented.
This review covers the K2.7 Code model, the Kimi Code CLI platform, real user experiences from Reddit and developer communities, and a direct comparison against DeepSeek V4 Pro and Claude Opus 4.8.
Learn about Kimi Code
Moonshot AI is a Beijing-based artificial intelligence company founded in March 2023. The company launched the original Kimi chatbot in October 2023 with a then-groundbreaking 128K-token context window, and has since grown to more than 36 million monthly active users. The company is backed by Alibaba, Tencent, and China Mobile, and was valued at approximately $20 billion following a funding round that closed in May 2026.
The K2 model family has moved fast. Five major releases arrived in under a year K2 base in July 2025, K2 Thinking in November 2025, K2.5 in January 2026, K2.6 in April 2026, and K2.7 Code in June 2026. Each release built on the same trillion-parameter MoE backbone while targeting a specific capability gap. K2.7 Code bets that token efficiency at the inference layer is now the most meaningful lever available without a full architecture change. That is a sensible hypothesis for teams running agentic coding pipelines at scale.
Kimi Code refers to two overlapping things: the K2.7 Code model itself, and the Kimi Code CLI a terminal-first coding agent subscription platform that wraps the model for developers who want a production-grade alternative to Claude Code.

How Kimi K2.7 Code Works
The architecture is a Mixture-of-Experts design with 1 trillion total parameters and 32 billion active parameters per token. The routing mechanism selects eight specialists from a pool of 384 expert subnetworks for each input token, plus one shared expert that remains active across all inputs. This design preserves a massive parameter ceiling while keeping per-token compute costs close to what a 32B dense model would require.
Here is the full technical profile at a glance:
| Specification | Detail |
|---|---|
| Total parameters | 1 trillion |
| Active parameters per token | 32 billion |
| Expert count | 384 (8 selected per token + 1 shared) |
| Context window | 256,000 tokens |
| Vision encoder | MoonViT (400M parameters) |
| Quantization | Native INT4 |
| License | Modified MIT |
| API pricing | $0.95 input / $4.00 output per million tokens |
| Release date | June 12, 2026 |
The 256K Context Window What It Actually Means for Codebases
A 256K context window fits roughly 200,000 lines of code in a single session, which covers most mid-sized repositories without chunking. This is larger than GPT-4o’s 128K window and matches the Claude 3.5 Sonnet generation. For developers processing large codebases, full documentation sets, or multi-file refactors, this eliminates a class of workflow friction that smaller-context models require workarounds for.
The limitation is real, however. Context degradation at extreme lengths what some developers call “lost in the middle” appears once the full window fills. The model loses thread of content injected in the middle of a very large context. Moonshot’s recommended workaround is agentic file reading: instead of pasting an entire repository at once, the model fetches specific modules sequentially, reading only what each step of the task requires.
Preserve Thinking and Multi-Turn Workflows
Most reasoning models discard their internal chain-of-thought between conversation turns. K2.7 Code keeps it. The Preserve Thinking feature carries reasoning forward across turns, which means the model can reference why it made an architectural decision in turn one when addressing an edge case raised in turn three. For multi-step coding workflows where context about reasoning matters as much as the output itself, this is a meaningful difference from models that start reasoning fresh each turn.
Kimi Code CLI The Subscription Platform
The Kimi Code CLI is Moonshot’s terminal-first coding agent, positioned as a direct competitor to Claude Code and Aider. It is open-source under the Apache 2.0 License and available on GitHub. Subscription plans start at $19/month, with higher tiers unlocking increased API call quotas within rolling 5-hour windows.
The token quota system allocates 300 to 1,200 API calls per 5-hour window depending on the plan tier, with a maximum concurrency of 30. This is fine for most developer workflows but becomes a constraint for automated pipelines running continuously overnight. Teams running heavy batch jobs need to account for this before committing.
A HighSpeed Mode began rolling out on June 15, 2026, delivering up to 180 tokens per second on coding tasks with median-length inputs, and up to 260 tokens per second on shorter-context tasks roughly six times faster than the standard inference mode.
The CLI integrates with vLLM, SGLang, and standard OpenAI-compatible endpoints, which means it works as a backend for Cline, Roo, Kilo, and Aider by base-URL swap. Teams already running Claude Code infrastructure can route to the Kimi API without reconfiguring the entire toolchain.
What Real Users Say About Kimi Code
Developer communities on Reddit and in published usage reports have generated a consistent body of feedback on the K2 series. The patterns below come from documented accounts across r/LocalLLaMA, r/ChatGPTCoding, Medium, and dev.to published through June 2026.
How developers are actually using it. The dominant use case documented across forums is high-volume agentic coding pipelines where API cost at scale is the deciding factor. Developers using Kimi as a backend for automated code generation, refactoring tasks, and multi-file edits report it as a viable drop-in for Claude at a fraction of the cost. A 30-day usage report published on Medium in May 2026 by developer Manu Nayyar described switching entirely from Claude to Kimi K2.6 for daily coding work, noting that Kimi costs roughly one-eighth of Claude for API usage and completes tasks that Claude would abandon halfway through.
The outcome multiple users reported. The most consistently documented result is cost reduction without a proportional quality drop on standard coding tasks. Developers running high-volume pipelines report 75–90% reductions in API spend after switching from GPT-5.2 equivalents, based on aggregated Reddit feedback compiled by aitooldiscovery.com in June 2026. For batch processing and multi-agent orchestration, this pricing gap compounds significantly over a month of production usage.
The positive surprise. The agentic tool call support surprised developers the most. The K2 series handles 200–300 sequential tool calls in a single agentic workflow, which is a capability ceiling that regularly comes up in r/ChatGPTCoding threads comparing Kimi to GPT-5.2. For developers building automated pipelines that chain many tool calls together, this volume is meaningfully higher than what many competing models support without hitting rate or context limits.
The consistent disappointment. Verbose outputs remain the most documented friction point. Multiple Reddit threads describe Kimi as over-explaining its reasoning when users want direct answers. The recurring phrase in r/ChatGPTCoding is “ask it a yes/no question and it writes three paragraphs.” The over-engineering tendency appears in coding tasks too a simple file-rename script returned by Kimi K2.6 came back with a full CLI interface, progress bars, and error logging, according to the Nayyar usage report. The practical fix documented by multiple users is adding “Keep it simple. No unnecessary abstractions.” as a standing instruction in the system prompt.
Kimi K2.7 Code vs the Competition
Two comparisons matter most for developers evaluating Kimi Code in June 2026. The first is against DeepSeek V4 Pro, the structurally closest open-weight alternative. The second is against Claude Opus 4.8, the frontier closed model that Kimi most directly undercuts on price.
Kimi K2.7 Code vs DeepSeek V4 Pro
Both are open-weight Chinese MoE models targeting coding and agentic workflows. Both are available on Hugging Face with permissive commercial licenses. The practical difference comes down to three things: price, benchmark transparency, and self-hosting cost.
DeepSeek V4 Flash is cheaper than K2.7 Code at $0.14/$0.28 per million input/output tokens roughly seven times cheaper on output. For teams running pure volume with looser quality requirements, DeepSeek V4 Flash wins the cost calculation outright. DeepSeek V4 Pro competes closer to K2.7 Code on capability, and the choice between the two comes down to evals on a specific codebase rather than any universal benchmark, since both labs publish results through proprietary or partially controlled suites.
Where K2.7 Code distinguishes itself is the Preserve Thinking feature and the MCP tool-use scores on Moonshot’s MCP Atlas benchmark. Agentic pipelines that require multi-turn reasoning continuity may favor K2.7 Code over DeepSeek’s current architecture.
Plans Kimi K2.7 Code vs Claude Opus 4.8
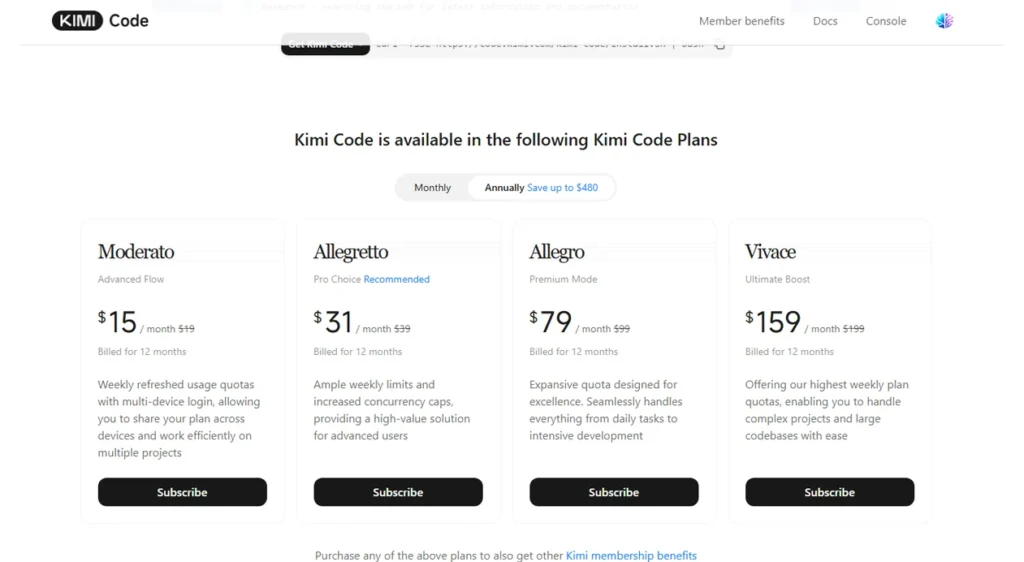
This is the comparison that frames the Kimi Code pitch most clearly. The gap is structural, not marginal.
| Kimi K2.7 Code | Claude Opus 4.8 | |
|---|---|---|
| Input price (per 1M tokens) | $0.95 | $5.00 |
| Output price (per 1M tokens) | $4.00 | $25.00 |
| Context window | 256K tokens | 200K tokens |
| Open weights | Yes (Modified MIT) | No |
| Self-hosting | Yes | No |
| Independent benchmark submission | None as of June 15, 2026 | Yes (SWE-bench, GPQA) |
| Regional availability | Global | US restrictions on Fable 5 tier |
| Kimi Code Bench v2 score | 62.0 | 67.4 |
| MLS Bench Lite score | 35.1 | Not published |
Claude Opus 4.8 leads on the hardest single-shot reasoning tasks and on independent benchmark suites. The SWE-bench Pro gap between them is real and documented. For code review, architecture decisions, and tasks where the cost of a wrong output is high, Claude’s reasoning advantage justifies the price premium.
For everyday code generation, refactoring, and automated pipelines that run hundreds of tasks per day, the 5x price difference makes K2.7 Code the more defensible choice for most teams that have validated quality on their specific workload.
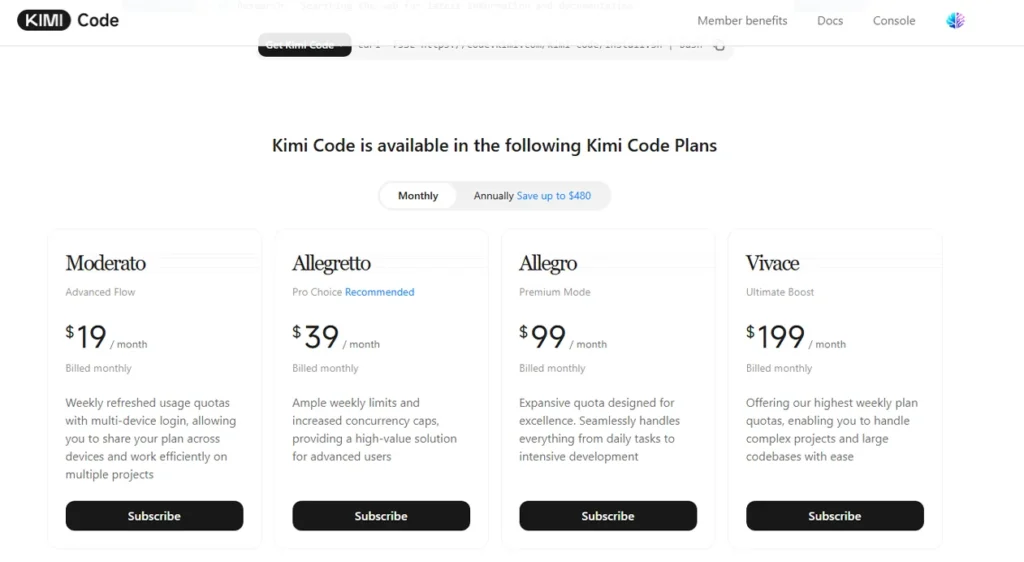
The Benchmark Caveat Every Developer Should Know
The benchmark picture for K2.7 Code carries a caveat that matters for purchasing decisions. Every number Moonshot published at launch the 21.8% gain on Kimi Code Bench v2, the 11.0% improvement on Program Bench, the 31.5% gain on MLS Bench Lite comes from proprietary suites that Moonshot designed and administered. As of June 15, 2026, no results from K2.7 Code appear on any publicly audited leaderboard, including SWE-bench Verified, DeepSWE, Terminal-Bench 2.0, or GPQA Diamond.
This does not mean the numbers are wrong. The K2.6 predecessor did submit to independent suites and performed well. The pattern here is hard to miss, though: vendor-designed benchmarks tend to reward the behaviors a vendor trained for, which makes cross-model comparisons unreliable until independent submissions arrive.
The practical implication is straightforward. Run K2.7 Code on a representative sample of your actual workload before standardizing on it. Moonshot’s numbers are useful for tracking improvement within the K2 family. They are not reliable for comparing K2.7 Code against Claude or GPT-5.5 on the same scale.
Pros, Cons, and What Makes Kimi Code Different
Pros Kimi ai
- API pricing at roughly 5x less than Claude Opus 4.8 This is the most consistently documented reason developers adopt Kimi K2. Developers running high-volume pipelines on Reddit and in Medium usage reports cite 75–90% reductions in API spend as the primary motivation for switching.
- Agentic tool call volume Support for 200–300 sequential tool calls in a single workflow gives K2.7 Code an edge in automated pipelines. This is the feature most often mentioned in r/LocalLLaMA and r/ChatGPTCoding threads where developers compare Kimi against GPT-5.2 equivalents.
- Open weights under a Modified MIT license Self-hosting removes API-level data exposure entirely. Teams with data governance concerns about sending proprietary code to a Chinese-owned API can deploy on air-gapped infrastructure, which is not an option with any closed frontier model.
- Preserve Thinking across conversation turns Carrying internal reasoning forward across turns is not standard behavior in competing models. For multi-step refactoring sessions where architectural context from earlier turns matters, this reduces repeated explanation and prompt overhead.
- 30% reduction in reasoning token usage vs K2.6 In long agentic loops, this directly lowers cost and latency on every step not just benchmarked tasks.
Cons Kimi ai
- Verbose outputs with no reliable fix. The over-explanation pattern is the most documented complaint across Reddit and developer forums. Adding “Keep it simple. No unnecessary abstractions.” to system prompts helps but does not eliminate the tendency. Users who need concise direct outputs still report friction.
- No independent benchmark submission as of June 15, 2026. Every K2.7 Code performance number comes from Moonshot’s own proprietary suites. This makes it difficult to validate claims against Claude or GPT-5.5 on a neutral scale until third-party results appear.
- “Lost in the middle” context degradation at extreme lengths. Dumping a very large repository into a single context window causes the model to lose thread of middle-injected content. The workaround agentic sequential file reading adds workflow complexity that some teams find difficult to implement consistently.
- Chinese company data exposure on hosted API. Privacy concerns appear in nearly every Kimi thread on Reddit. For teams sending proprietary code through the hosted Moonshot API, the data governance question has no simple answer. Self-hosting resolves it but requires significant hardware investment.
- Self-hosting hardware demands. Running the full-precision model requires approximately 340 GB of combined RAM and VRAM. INT4 quantization reduces this substantially, but it still demands a multi-GPU server or high-end cluster not a realistic option for individual developers or small teams.
What Makes Kimi Code Different
The open-weights-plus-CLI combination at this price point is the genuine differentiator. DeepSeek V4 Pro is also open-weight and cheaper, but does not currently offer a comparable first-party CLI agent that competes directly with Claude Code’s interface. Claude Code and GPT-5.5 offer polished managed experiences but are closed, expensive, and cannot be self-hosted. Kimi Code is the only product in this category that offers a terminal-first coding agent, open model weights, commercial-friendly licensing, and sub-$1 per million input token pricing in a single package.
The Preserve Thinking feature adds a secondary differentiator for teams running long multi-turn agentic sessions. No directly competing open-weight model in June 2026 replicates this behavior.
My opinion about Kimi K2.7 Code
After going through the research and the recurring feedback above, my assessment is that Kimi K2.7 Code earns its place for development teams running high-volume agentic pipelines where API cost is a genuine constraint. The 5x price advantage over Claude Opus 4.8 is not a marketing claim it is a number that compounds into real budget differences at production scale, and the agentic tool call ceiling is legitimately higher than most competing options at this price.
Where I would not recommend it without qualification is for teams doing their highest-stakes reasoning work architecture reviews, security audits, or tasks where a wrong output has downstream consequences. The benchmark caveat is real: no independent submission exists as of this writing, and the gap against Claude on hard reasoning tasks is documented in the K2.6 generation. That gap likely persists in K2.7 Code.
For cost-sensitive teams who have validated quality on their specific workload, Kimi Code is worth serious evaluation. For teams where output quality on the hardest tasks is non-negotiable and budget is secondary, Claude Opus 4.8 remains the stronger choice.
The Kimi chatbot at kimi.com offers a free web tier with no message limits for basic chat. Kimi K2.7 Code is not available on the free tier. Access to K2.7 Code requires either a Kimi Code CLI subscription starting at $19/month or direct API access billed at $0.95 per million input tokens and $4.00 per million output tokens. The model weights are freely downloadable from Hugging Face under a Modified MIT license for teams with the hardware to self-host.
Both are terminal-first coding agents. Kimi Code is open-source under Apache 2.0 and backed by the K2.7 Code open-weight model. Claude Code is a closed managed service backed by Anthropic’s Claude Opus and Sonnet models. Kimi Code’s API pricing is roughly 5x cheaper than Claude Opus 4.8. Claude leads on independent benchmark scores and hardest-task reasoning. Kimi Code allows full self-hosting; Claude Code does not. Teams running high-volume pipelines on a budget tend to favor Kimi; teams needing the strongest reasoning on complex tasks tend to favor Claude.
Kimi K2.7 Code API pricing sits at $0.95 per million input tokens and $4.00 per million output tokens as of June 2026. Cached input tokens cost significantly less. The Kimi Code CLI subscription starts at $19/month with token quotas of 300 to 1,200 API calls per 5-hour rolling window depending on the tier. Free API credits are available to new users on signup. Pricing has changed multiple times across 2026 always confirm current rates on platform.kimi.com before committing.
Yes, but only through self-hosting. The K2.7 Code weights are available on Hugging Face under a Modified MIT license, which allows deployment on air-gapped infrastructure with no data leaving your environment. Using the hosted Kimi API sends data to Moonshot AI servers, which are subject to Chinese law. Teams with strict data governance requirements should treat the hosted API as unsuitable for proprietary code and evaluate self-hosting instead.
Running the model in full precision requires approximately 340 GB of combined RAM and VRAM based on the hardware profile of the architecturally identical K2.6. Native INT4 quantization reduces this substantially and makes deployment feasible on multi-GPU servers with 64 GB or more of VRAM for the active parameter layer. The model is compatible with vLLM, SGLang, and KTransformers for inference serving. Individual developers on consumer hardware will find local deployment impractical without significant investment.
On Moonshot’s own benchmarks, K2.7 Code scores 62.0 on Kimi Code Bench v2 against GPT-5.5’s 69.0, and 35.1 on MLS Bench Lite against GPT-5.5’s 35.5 the gap has narrowed considerably. No independent benchmark results exist for K2.7 Code as of June 15, 2026, so direct comparisons on neutral suites are not yet possible. GPT-5.5 is a closed generalist frontier model with broader reasoning strengths. K2.7 Code is an open-weight specialist with lower cost and self-hosting flexibility. For high-volume coding workloads where cost matters, K2.7 Code is the stronger value; for broad reasoning tasks, GPT-5.5 leads.
kimi Websites and apps
Similar AI Tools
